The Mystery of Hy3: Why a Mediocre Model is Dominating OpenRouter’s Rankings
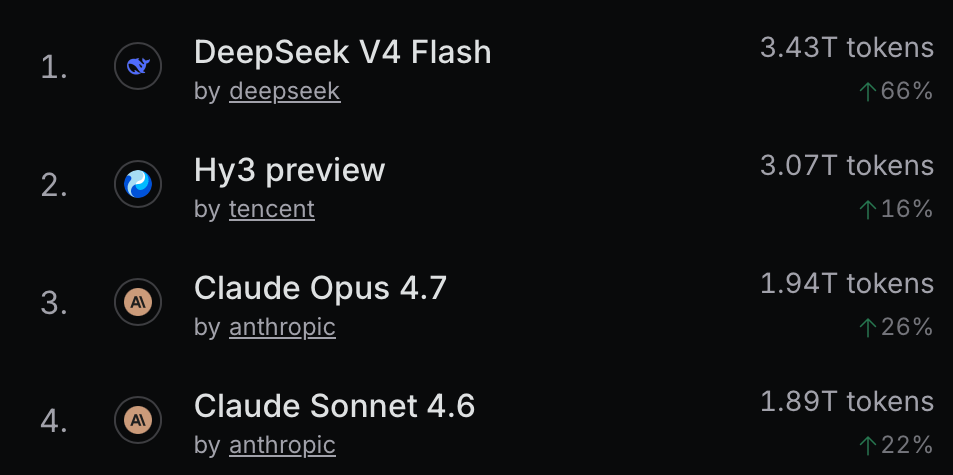
Table of Contents
An Unexpected Leader in the LLM Race
In the volatile ecosystem of Large Language Models (LLMs), popularity is usually a proxy for performance. When a model climbs the rankings of a major aggregator like OpenRouter—which provides a unified API for dozens of models—it typically signals a breakthrough in reasoning, coding capability, or a massive drop in price for a top-tier performer. However, the recent surge of “Hy3 preview” defies this logic.
OpenRouter’s AI Model Rankings have become a critical industry barometer because they track actual token usage rather than synthetic benchmarks. While the labs themselves keep usage data guarded, OpenRouter’s transparency reveals a peculiar anomaly: Hy3 preview is currently outstripping industry favorites, including Claude, by a significant margin in terms of total token volume.
On the surface, the rise of DeepSeek Flash V4 makes sense. It is an open-source powerhouse that balances speed and cost while punching well above its weight in performance. But Hy3 is a different story. Developed by Chinese conglomerate Tencent, Hy3’s presence on Hugging Face is sparse, and its own benchmark results are underwhelming compared to other Chinese open-weights models. It isn’t a “diamond in the rough”—initial testing suggests its quality doesn’t remotely approach the levels of Claude Opus or GPT-4o.
Tracing the Volume Spike
The mystery deepens when examining the timeline. Hy3 preview first appeared as a free endpoint on OpenRouter around May 6. Naturally, free models attract a crowd, but the usage didn’t crater once the free trial ended. Instead, the data shows a steady, organic climb even after the model transitioned to a paid SKU on May 8. This suggests that a dedicated set of users is finding specific value in Hy3, despite its mediocre general benchmarks.
One might assume this is the result of a specific application switching its default model to Hy3—a phenomenon previously seen when Kilo Code integrated Grok Code Fast 1. However, OpenRouter’s data indicates that app-driven activity constitutes only a small fraction of Hy3’s volume. The usage is distributed, implying a broader, if unexplained, appeal.
The Infrastructure Angle: SiliconFlow and the Price War
To understand why users are choosing a mediocre model, one has to look at the plumbing. While most open-weight models on OpenRouter are served by a dozen different providers to ensure redundancy and price competition, Hy3 preview is exclusively served by SiliconFlow, a Singapore-based provider. Until the arrival of Hy3, SiliconFlow had a relatively quiet profile on the platform.
The financial incentive is clear: Hy3 preview is priced at approximately $0.066 per million input tokens, undercutting DeepSeek V4 Flash’s $0.10 per million. In an era where autonomous coding agents are consuming millions of tokens per hour, a 34% price difference can be the deciding factor for a developer operating on a tight budget, provided the model is “good enough” for the specific task.
The Hidden Impact of Prompt Caching
However, the raw price per token doesn’t tell the whole story. The modern LLM landscape is increasingly defined by prompt caching. Because LLM calls are stateless, every new turn in a conversation requires the model to re-process the entire previous history. To combat this, providers now cache previous inputs, drastically reducing costs for long conversations.
Most major providers, including OpenAI and Google, offer cache reads at roughly 10% of the standard input cost. The interaction between Hy3’s base pricing and SiliconFlow’s specific caching implementation may be creating a cost-efficiency loop that makes it more attractive for high-context tasks—such as analyzing massive PDF libraries or long codebases—than models that are nominally “smarter” but more expensive to scale.
Ultimately, the rise of Hy3 serves as a reminder that in the AI economy, “best” is not always defined by the highest benchmark score. Sometimes, it is simply a matter of who can offer the most tokens for the fewest cents, packaged through the right provider.


