How Facebook Solved the Massive Scale of Real-Time Monitoring with Gorilla
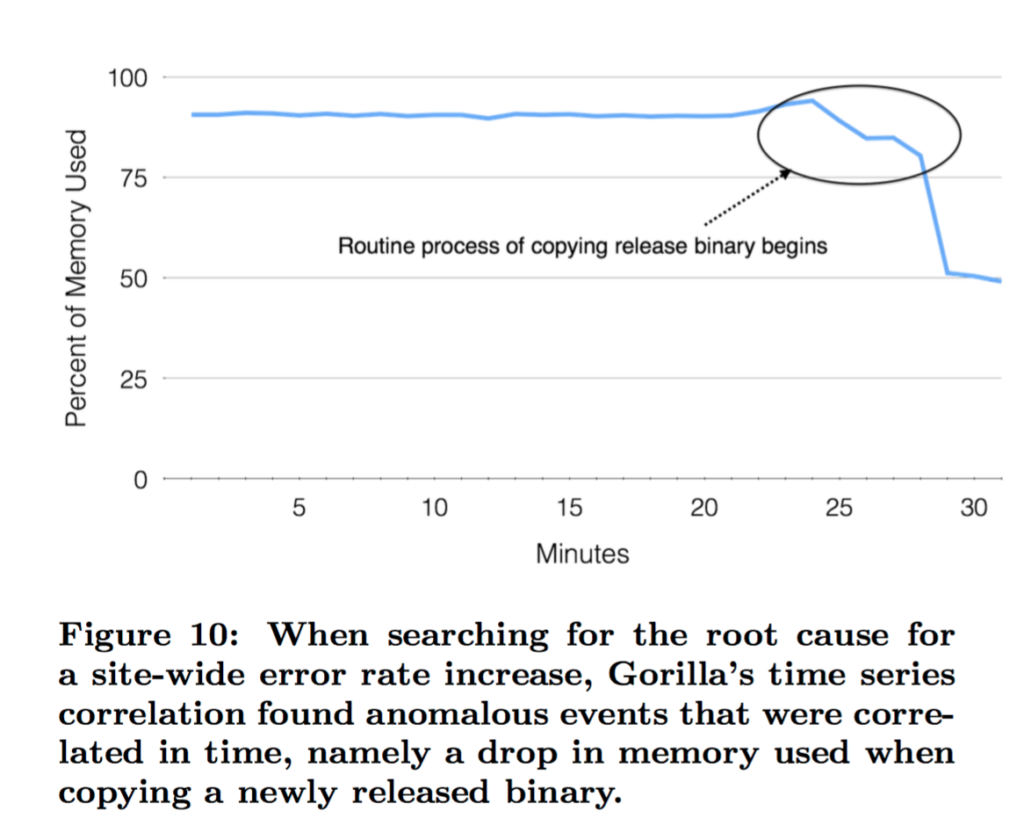
Table of Contents
The Challenge of Infinite Metrics
In the world of hyper-scale infrastructure, monitoring is less about checking a few dashboards and more about managing a relentless firehose of data. For Facebook, the sheer volume of time series data—metrics collected over time from every server and service in their fleet—eventually outpaced the capabilities of traditional storage solutions. The result was Gorilla, a specialized in-memory time series database (TSDB) designed to provide the kind of low-latency access that makes real-time troubleshooting possible.
Gorilla doesn’t try to replace long-term storage. Instead, it acts as a massive write-through cache, sitting in front of an HBase data store. While HBase handles the historical archive, Gorilla keeps the most recent 26 hours of data live in RAM. This architectural split allows engineers to query recent spikes and anomalies with incredible speed without being bogged down by the latency of disk-based lookups.
Cracking the Compression Code
The most significant hurdle for any in-memory system is the cost of RAM. To store 26 hours of global monitoring data, Facebook couldn’t simply throw more hardware at the problem; they needed a way to make the data smaller. The team developed a custom compression algorithm that achieves an average 12x reduction in size, allowing them to fit massive datasets into a manageable number of nodes.
The magic of Gorilla’s compression lies in how it handles the two components of a data point: the timestamp and the value.
Taming the Timestamps
Most monitoring data is predictable. If a server logs a metric every 60 seconds, the gap between points is almost always 60 seconds. Gorilla leverages this by using “delta-of-deltas” encoding. Rather than storing the full timestamp, the system records the difference between the current interval and the previous one. When the interval is exactly the same, the delta-of-delta is zero, which can be represented by a single bit.
According to the team’s findings, roughly 96% of all timestamps in their production environment were compressed down to a single bit, drastically reducing the memory footprint of the time axis.
XORing the Values
Compressing the actual values is trickier because metrics can fluctuate. However, Facebook observed that in most time series, values don’t jump wildly from one second to the next; they tend to stay close to their previous state. Instead of traditional delta encoding, Gorilla uses an XOR-based approach.
By XORing the current value with the previous one, the system identifies which bits have actually changed. If the values are identical, the result is zero—again, compressible to a single bit. About 51% of all values in their system were compressed this way. When values do change, the system only stores the meaningful XOR’d bits, keeping the overhead minimal.
Scaling Out and Root Cause Analysis
The system is built on a share-nothing architecture, utilizing a C++ standard library unordered map for its core data structure. This design allows Facebook to scale the cluster horizontally. When the data grows, they simply add more hosts and tune the sharding function to distribute the unique string keys across the new hardware.
The impact of this speed is most evident in the tools built atop Gorilla. One of the most powerful additions is a correlation engine that calculates the Pearson Product-Moment Correlation Coefficient (PPMCC). This allows engineers to compare a failing service’s metrics against thousands of other time series to find similarly shaped patterns.
Essentially, the engine helps answer the critical question: “What else broke at the exact same time as my service?” By identifying correlated spikes across the infrastructure, Facebook can automate root-cause analysis, turning a manual search through logs into a data-driven discovery process. Since its implementation, the system has proven to be over 70 times faster than the legacy infrastructure it replaced.