Beyond the Neural Net: The Hidden Architecture and Cultural Baggage of Speaking Machines
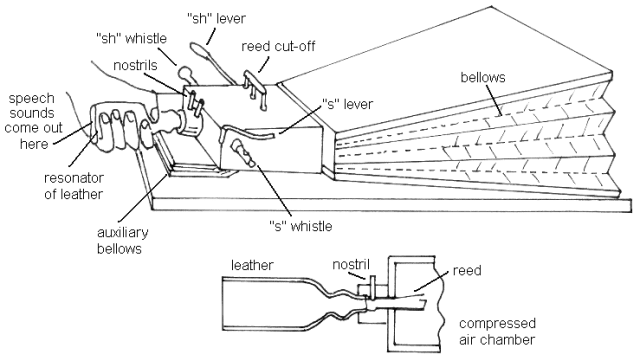
Table of Contents
The Mechanical Roots of Artificial Voice
In the current era of hyper-realistic AI clones and seamless neural text-to-speech (TTS), it is easy to forget that the quest to make machines speak began not with silicon, but with bellows and leather. Long before the first line of code was written, inventors were attempting to reverse-engineer the human vocal tract through purely physical means. The 18th-century efforts of Wolfgang von Kempelen represent the dawn of this ambition, utilizing a system where air was forced through a reed and shaped by a leather membrane to simulate phonemes. This primitive architecture—an oscillator source filtered by a simulated vocal tract—remains the conceptual bedrock for how we approach synthetic speech today.
By the time we reached the 19th century, inventors like Faber sought to refine this process, evolving the mechanical bellows into the ‘Euphonia.’ This device utilized sixteen keys to trigger different phonemes, though it highlighted a recurring theme in the history of the medium: the reliance on a human operator. To mitigate the ‘uncanny valley’ effect of a clanking machine, Faber famously adorned the device with a woman’s face and dress, an early attempt to mask the coldness of technology with a curated, approachable persona.
From Voderettes to Diphone Synthesis
The mid-20th century saw the transition from mechanical reeds to electronic oscillators. The VODER, debuted at the 1939 World’s Fair, was a landmark in monophonic synthesis. It combined a noise generator with a foot pedal for pitch control, but its success relied entirely on the ‘Voderettes’—highly trained women who spent years mastering the complex controls to produce intelligible speech. While the inventors received the accolades, the labor of these operators was largely erased from the historical record, establishing a precedent for the invisible human work that often underpins ‘automated’ technology.
As the industry moved toward the late 20th century, the approach shifted from simulating the vocal tract (formant synthesis) to splicing together actual human recordings. This concatenative method, pioneered by systems like Italy’s MUSA, utilized ‘diphones’—recordings of the transitions between phonemes. By stitching together thousands of these small samples and smoothing them with digital signal processing (DSP), developers created the robotic yet intelligible voices that defined GPS systems and automated phone menus for decades.
The Legacy of Macintalk and the ‘Say’ Command
For many tech enthusiasts, the most visceral memory of early synthesis is Apple’s Macintalk. Launched in 1984, this formant-based system allowed the Macintosh to introduce itself to the world, sparking a level of public fascination that bordered on the religious. Throughout the 1990s, users experimented with voices like ‘Bad News’ and ‘Princess,’ treating the computer’s voice as a toy rather than a tool.
With the introduction of Mac OS X (Cheetah) in 2001, Apple provided a command-line interface to this framework via the say command. While most users utilized it for simple text-to-speech, the underlying framework contained a hidden, low-level Domain Specific Language (DSL) for controlling prosody. By manipulating duration (D) and pitch curves (P) at the phoneme level, developers could craft expressive, albeit synthetic, speech patterns that bypassed the standard text-to-speech pipeline.
The Cultural Bias of the Synthetic Voice
The evolution of these machines reveals more than just technical progress; it reflects deep-seated cultural biases. From Faber’s Euphonia to the modern ubiquity of female-coded AI assistants like Siri and Alexa, there has been a consistent industry trend toward feminizing synthetic voices to make them appear less threatening and more subservient. Similarly, the obsession with making machines sing—from the haunting ‘Daisy Bell’ sequence in 2001: A Space Odyssey to modern LLM-driven vocals—suggests an implicit belief that singing is the ultimate benchmark of human-like intelligence.
Today, we have entered the era of generative neural networks, where samples are predicted individual-by-individual. While these systems offer unprecedented realism, the foundational history of speaking machines serves as a reminder that every ‘intelligent’ voice is built upon a legacy of human operation, gendered stereotypes, and a century of iterative engineering.


